Amazon E-Commerce Analysis
DESCRIPTION
• Amazon is an online shopping website that now caters to millions of people everywhere. Over 34,000 consumer reviews for Amazon brand products like Kindle, Fire TV Stick and more are provided.
• The dataset has attributes like brand, categories, primary categories, reviews.title, reviews.text, and the sentiment.
• Sentiment is a categorical variable with three levels "Positive", "Negative“, and "Neutral".
• For a given unseen data, the sentiment needs to be predicted.
• So, I required to predicted the Sentiment or Satisfaction of a purchase based on multiple features and review text.
• First, I perform an EDA on a dataset using Pandas, NumPy, and Matplotlib libraries.
• The NLTK library was used for preprocessing to categorise the positive, negative, and netural reviews.
• For creating TF-IDF (term frequency-inverse document frequency), Multinomial Naive Bayes Classifier and Count Vectorizer we have used SKLearn framework.
• After running Multinomial Naive Bayes Classifier Everything is classified as positive because of the class imbalance as seen above.
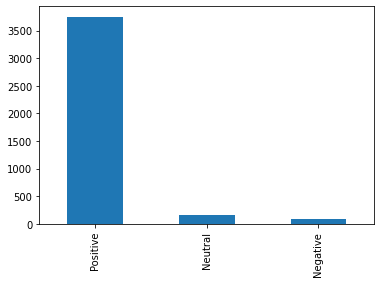
Imbalanced Dataset
• To tackle the imbalance problem, I have used oversampling techniques.
• Imblearn library was used for oversampling techinque.
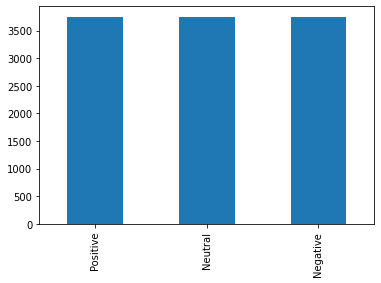
Balanced Dataset
• The following text preprocessing methods are implemented to convert raw reviews to cleaned review making it easier to do feature extraction in the next step.
1. Remove non-character such as digits and symbols.
2. Convert to lower case.
3. Remove stop words such as "the" and "and" if needed.
4. Convert to root words by stemming if needed.
CountVectorizer with Multinomial Naive Bayes:
1. Now that I have cleaned all reviews, the next step is converting the reviews into numerical representations for a machine learning algorithm.
2. I will use CountVectorizer, which implements both tokenization and occurrence counting in a single class provided by the Sklearn library. The output is a sparse matrix representation of the document.
3.Multinomial Naive Bayes accuracy score is 93.6%.
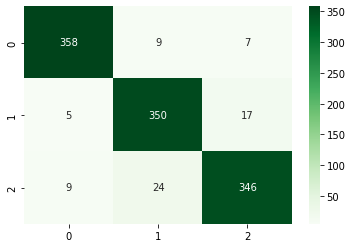
Counter Vectorised Confusion Matrix
TfidfVectorizer with Logistic Regression:
1.Some words might appear quite frequently but have a very less or negligible meaningful information about the sentiment for a particular review. Instead of using occurance counting we will use tf-idf transform to
scale down the impact of frequently appearing words in a given corpus.
2.In sklearn library we will use TfidfVectorizer which implements both tokenization and tf-idf weighted counting in a single class.
3.TfidfVectorizer with Logistic Regression accuracy is 97%.

TF-Vector Confusion Matrix
TfidfVectorizer with Linear SVM by using SGD:
1.Some words might appear quite frequently but have a very less or negligible meaningful information about the sentiment for a particular review. Instead of using occurance counting we will use tf-idf transform to
scale down the impact of frequently appearing words in a given corpus.
2.In sklearn library we will use TfidfVectorizer which implements both tokenization and tf-idf weighted counting in a single class.
3.TfidfVectorizer with Linear SVM by using SGD accuracy is 98%.
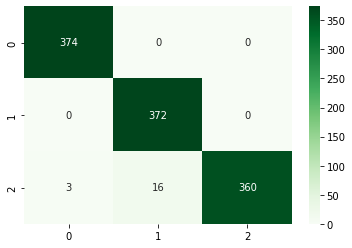
TF-SVM Confusion Matrix
XGBoost Classifier:
1.Some words might appear quite frequently but have a very less or negligible meaningful information about the sentiment for a particular review. Instead of using occurance counting we will use tf-idf transform to
scale down the impact of frequently appearing words in a given corpus.
2.In sklearn library we will use TfidfVectorizer which implements both tokenization and tf-idf weighted counting in a single class.
3.XGBoost classifier accuracy is 92%.
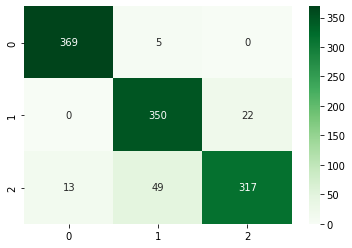
XG Boost Classifier Confusion Matrix
Pipeline and GridSearch:
1. I build a pipeline in the Sklearn library to streamline the workflow and use GridSearch on the pipeline model to implement hyperparameter tuning for both the vectorizer and classifier at once.
2. Gridsearch accuracy is 99.8%.
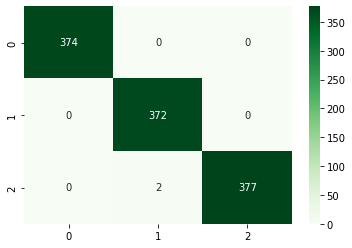
Gridsearch Confusion Matrix
Random Forest Classifier:
•Another common approach of word embedding is the prediction based embedding like Word2Vec model. Briefly, Word2Vec is a combination of two techniques: Continuous Bag of Words (CBoW) and Skip-Gram
model. Both are Shallow Neural Networks which learn weights for the word vector representations.
•Here,I will train Word2Vec model to create our own word vector representation using gensim library. Then we will fit the feature vectors of the reviews to the Random Forest Classifier.
•Here's the workflow of this
part: -
1.Parse review text to sentences (Word2Vec model takes a list of sentences as inputs).
2.Create vocabulary list using Word2Vec model.
3.Transform each review into numerical representation by computing average feature vectors of words therein
4.Fit the average feature vectors to Random Forest Classifier
•Random Forest accuracy is 99.5%
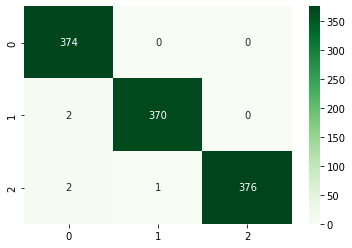
Random Forest Confusion Matrix
LSTM:
•Long Short Term Memory(LSTM) Networks are a special kind of the Recurrent Neural Networks(RNN) capable of learning long-term dependencies. LSTM can be very useful in text mining problems as it involves
dependencies in the sentences which can be caught in the "memory" of the LSTM. Here, we will train a simple LSTM and LSTM with Word2Vec embedding for classifying the reviews into positive and negative
sentiments using Keras library.
•We need to preprocess the text data to 2D tensor before we begin fitting it into a simple LSTM. Firstly we will tokenize the corpus by considering only top words (top_words = 20000) and transforming reviews to
numerical sequences using the trained tokenizer. Lastly we will make it sure that all the numerical sequences have the same length (maxlen=100) for modelling by truncating the long reviews and padding shorter
reviews having zero values.
•For constructing a simple LSTM, we will use embedding class in Keras to building up the first layer. This embedding layer converts numerical sequence of words into a word embedding. We should also note that the
embedding class provides a convenient way to map discrete words into a continuous vector space but it doesn't take the semantic similarity of the words into account. The next layer is the LSTM layer with 128
memory units. Finally, we will use a dense output layer with a single neuron and a sigmoid activation function to make 0 or 1 prediction for the two classes (positive sentiment and negative sentiment). As it is a
binary classification problem log loss is used as the loss function(binary_crossentropy in Keras). ADAM optimization algorithm will be used.
•Here's the workflow in this part: -
1.Prepare X_train and X_test to 2D tensor.
2.Train a simple LSTM (embedding layer => LSTM layer => dense layer).
3.Compile and fit the model using log loss function and ADAM optimizer.
•Simple LSTM model accuracy is 99.3%
LSTM with Word2Vec Embedding:
1.In the simple LSTM model constructed above, the embedding class in Keras comes in handy for converting the numerical sequence of words into a word embedding but it doesn't take the semantic similarity of the
words into account. The model assigns random weights to the embedding layer and learn the embeddings by minimizing the global error of the network.
2. Instead of using random weights we will use pretrained word embeddings for initializing the weight of an embedding layer. Here, we will use the Word2Vec embedding trained in Part 4 for intializing the weights of
embedding layer in LSTM.
1. Load pretrained word embedding model.
2. Construct embedding layer using embedding matrix as weights.
3. Train a LSTM with Word2Vec embedding (embedding layer => LSTM layer => dense layer).
4. Compile and fit the model using log loss function and ADAM optimizer.
•LSTM with Word2Vec Embedding accuracy is 99.5%.
Get in Touch


